Go Compiler Tooling - Part 2
I gave a talk at GopherCon 2024 based on this post. The slides for the talk can be found here, and the generated SSA file can be found here.
This is a continuation of the first post on adding "four" loops to the Go compiler. Up until this point, we've modified the Go compiler to have 2 new statements, four loops and unless conditions, which behave as below:
In this post we'll take a look at some of the compiler tooling that Go provides to help us analyze our changes and see what sort of optimizations the compiler makes.
As mentioned in the previous post, the compiler converts the abstract syntax tree into an intermediate representation in Statis Single Assignment form. In SSA form, the program is represented as a directed graph of blocks, where each variable is only ever assigned once. Representing the code this way makes it easier to perform optimizations and translate to machine code. To get a better understanding of how the Go compiler does this, we can pass the GOSSAFUNC variable to the compiler with the function that we want to generate the SSA for. This will generate an html file that contains the AST, the SSA after each optimization pass, and the final machine code.
Using this code as the example:
We run:
which will generate a file named ssa.html. I've included the Go compiler flag -gcflags=-l to disable function inlining which will make the compiler's output easier to read and understand.
The generated file looks like this:

These are all the passes that the backend does which can be seen in the code here.
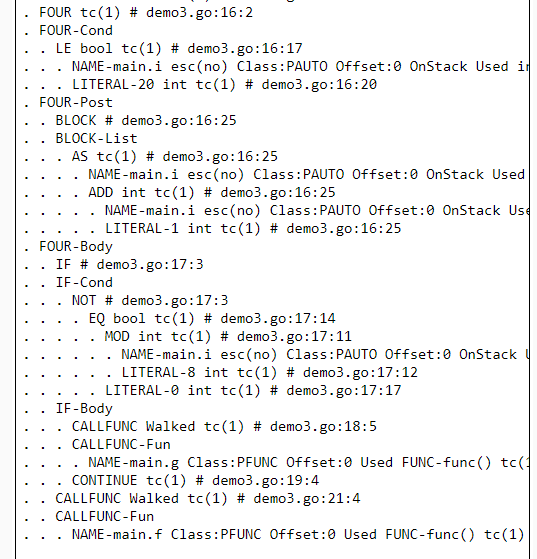
First we'll take a look at the AST section, where we can see the AST node for the four loop. Note that there is no unless node. This is because we desugared the unless condition into a negated if condition in walk step, which we see in the AST:
This AST is then converted to SSA form, which looks like this:

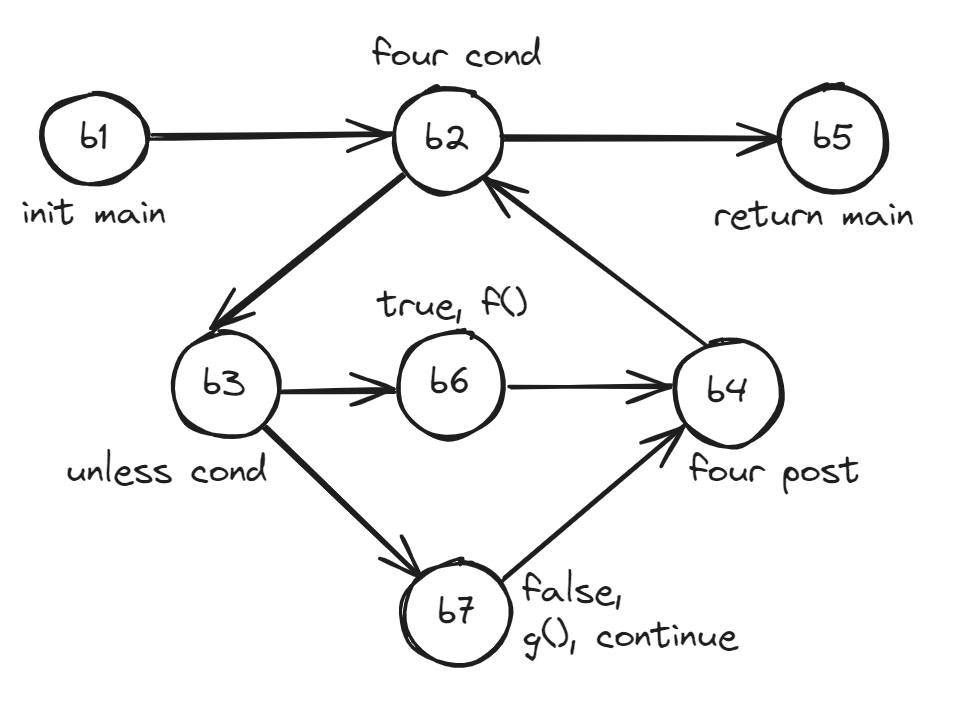
Note that each blocked is denoted by b{N}, and that these blocks correspond to the control flow graph we saw in the pervious post.
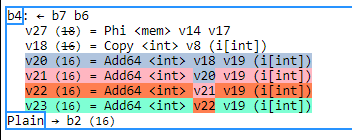
Focusing in on block 4, we can see the four loop post statement is executed 4 times like this by incrementing by 1 four times.
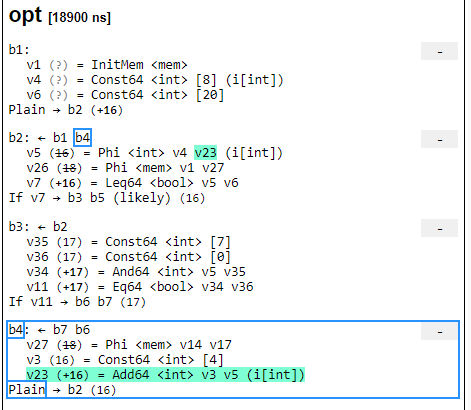
And if we take a look a few passes later after the opt pass, we can see that this has been optimized down to a single instruction that increments by 4.
Up until this point, all the optimization passes have been architecture independent. Eventually, we reach the lower pass, which will start to introduce architecture specific instructions and optimizations.

Another interesting optimization pass is the layout pass. This step reorders the blocks to group ones that flow into each other closer together. So far, each block has been in order from 1 to 7. But after the unless condition (block 3), we will always go to either block 6 or block 7. So these blocks are moved directly under block 3.
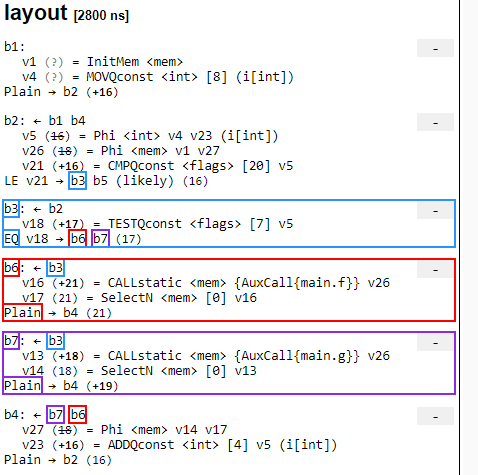
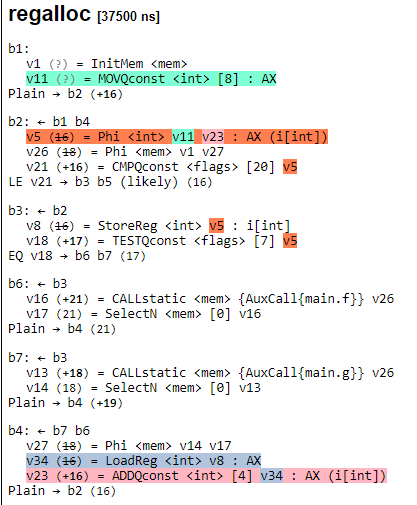
After this is another architecture specific optimization pass, regalloc where we start to allocate registers to variables. In our example, the AX register is used to store the i variable from the code.
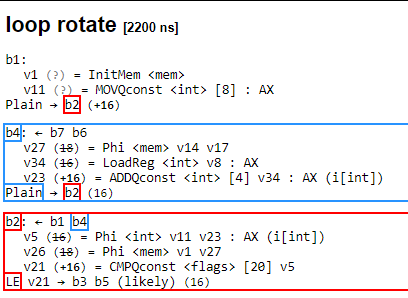
One of the final passes is the loop rotate pass, where the compiler moves the four loop post statement (block 4) to above the the four condition (block 2) to avoid having to jump back each iteration.
Finally, we reach the final pass, which is to convert the SSA to machine code. The resulting machine code looks like this:

By tracing through the instructions we can see how this will execute the original Go code, and which instructions correspond to which blocks.
And that's all there is! After this, the Go machine code is passed to the assembler to generate the actual machine code, which will be linked and then can be executed. If you're curious to see the full set of changes to implement the four loop and unless condition, you can take a look here. Thanks for reading!